TRADUCTION BRUNO BERTEZ LE 03 OCTOBRE 2025
Yves de NAKED CAPITALISM
Voici un article accablant et incontournable de Servaas Storm, qui explique comment l’IA ne parvient pas à tenir ses promesses de performance fondamentales, maintes fois vantées, et n’y parviendra jamais, malgré les investissements et la puissance de calcul qui lui sont consacrés. Pourtant, l’IA, que Storm appelle « information artificielle », continue d’engranger des valorisations bien supérieures à la frénésie des entreprises DOT-com, alors même que les erreurs sont en augmentation.
Par Servaas Storm, maître de conférences en économie à l’Université de technologie de Delft. Initialement publié sur le site web de l’Institut pour une nouvelle pensée économique.
Cet article soutient que
(i) nous avons atteint le « pic GenAI » en termes de modèles de langage de grande taille (LLM) actuels ; la mise à l’échelle (construction de plus de centres de données et utilisation de plus de puces) ne nous mènera pas plus loin vers l’objectif de « l’intelligence artificielle générale » (AGI) ; les rendements diminuent rapidement ;
(ii) l’industrie de l’IA-LLM et l’économie américaine dans son ensemble connaissent une bulle spéculative, qui est sur le point d’éclater.
Les États-Unis connaissent un essor économique exceptionnel, alimenté par l’IA : la bourse s’envole grâce aux valorisations exceptionnellement élevées des entreprises technologiques liées à l’IA, qui alimentent la croissance économique grâce aux centaines de milliards de dollars investis dans les centres de données et autres infrastructures d’IA.
L’essor des investissements dans l’IA repose sur la conviction que l’IA améliorera considérablement la productivité des travailleurs et des entreprises, ce qui propulsera leurs profits à des niveaux sans précédent.
Mais l’été 2025 n’a pas apporté de bonnes nouvelles aux passionnés d’intelligence artificielle générative (GenAI), tous enthousiasmés par la promesse exagérée de personnalités comme Sam Altman d’OpenAI, selon laquelle l’« intelligence artificielle générale » (AGI), le Saint Graal de la recherche actuelle en IA, serait imminente.
Examinons de plus près ce battage médiatique.
Déjà en janvier 2025, Altman écrivait : « Nous sommes désormais convaincus de savoir comment construire l’IAG ». L’optimisme d’Altman faisait écho aux déclarations de Microsoft, partenaire et principal bailleur de fonds d’OpenAI, qui avait publié en 2023 un article affirmant que le modèle GPT-4 présentait déjà des « étincelles d’IAG ».
Elon Musk (en 2024) était tout aussi confiant que le modèle Grok développé par sa société xAI atteindrait l’IAG, une intelligence « plus intelligente que l’être humain le plus intelligent », probablement d’ici 2025 ou au moins 2026.
Mark Zuckerberg, PDG de Meta, a déclaré que son entreprise s’engageait à « construire une intelligence générale complète », et que la superintelligence était désormais « en vue » .
De même, Dario Amodei , cofondateur et PDG d’Anthropic, a déclaré qu’une « IA puissante », c’est-à-dire plus intelligente qu’un lauréat du prix Nobel dans n’importe quel domaine, pourrait apparaître dès 2026 et inaugurer une nouvelle ère de santé et d’abondance — les États-Unis deviendraient un « pays de génies dans un centre de données », si… l’IA ne finissait pas par nous tuer tous.
Pour M. Musk et ses compagnons de route GenAI, le principal obstacle sur la voie de l’IA générale réside dans le manque de puissance de calcul (installée dans les centres de données) pour entraîner les robots IA, dû à l’absence de puces informatiques suffisamment avancées.
La demande croissante de données et de capacités de traitement de données nécessitera environ 3 000 milliards de dollars de capitaux rien qu’en 2028, selon Morgan Stanley. Cela dépasserait la capacité des marchés mondiaux du crédit et des produits dérivés . Poussés par l’impératif de remporter la course à l’IA avec la Chine, les propagandistes de GenAI sont convaincus que les États-Unis peuvent s’engager sur la voie pavée jaune de la Cité d’Émeraude de l’IA générale en construisant plus rapidement davantage de centres de données (une expression clairement « accélérationniste »).
Il est intéressant de noter que l’IAG est une notion mal définie, et peut-être davantage un concept marketing utilisé par les promoteurs de l’IA pour convaincre leurs bailleurs de fonds d’investir dans leurs projets.
En gros, l’idée est qu’un modèle d’IAG peut généraliser au-delà des exemples spécifiques contenus dans ses données d’entraînement, de la même manière que certains êtres humains peuvent effectuer presque n’importe quel travail après avoir appris quelques exemples, en tirant les leçons de l’expérience et en adaptant leurs méthodes si nécessaire. Les robots d’IAG seront capables de surpasser les humains, de créer de nouvelles idées scientifiques et de réaliser des opérations de codage innovantes, ainsi que des tâches courantes. Les robots d’IA nous diront comment développer de nouveaux médicaments pour soigner le cancer, lutter contre le réchauffement climatique, conduire nos voitures et cultiver nos cultures génétiquement modifiées.
Ainsi, dans un élan radical de destruction créatrice, l’IAG transformerait non seulement l’économie et le monde du travail, mais aussi les systèmes de santé, d’énergie, d’agriculture, de communication, de divertissement, de transport, de recherche et développement, d’innovation et de science.
Altman d’OpenAI s’est vanté que l’IA générale permette de « découvrir de nouvelles sciences », car « je pense que nous avons déchiffré le raisonnement des modèles », ajoutant qu’il « reste encore beaucoup de chemin à parcourir ». Il « pense que nous savons ce qu’il faut faire », affirmant que le modèle o3 d’OpenAI « est déjà plutôt intelligent » et qu’il a entendu des gens dire « Waouh, c’est comme un bon doctorat ». Annonçant le lancement de ChatGPT-5 en août, M. Altman a publié sur Internet : « Nous pensons que vous apprécierez GPT-5 bien plus que toute autre IA précédente. C’est utile, intelligent, rapide [et] intuitif. Avec GPT-5, c’est comme parler à un expert : un véritable expert de niveau doctorat dans tous les domaines dont vous avez besoin, à la demande, qui peut vous aider, quels que soient vos objectifs. »
Mais ensuite, les choses ont commencé à se dégrader, et assez rapidement.
ChatGPT-5 est une déception
La première mauvaise nouvelle est que ChatGPT-5, tant vanté, s’est avéré être un échec : des améliorations incrémentales intégrées à une architecture de routage , loin de la percée vers l’IA générale annoncée par Sam Altman. Les utilisateurs sont déçus. Comme le rapporte la MIT Technology Review : « Cette version, tant vantée, apporte plusieurs améliorations à l’expérience utilisateur de ChatGPT. Mais elle est encore loin d’atteindre l’IA générale. » Il est inquiétant de constater que les tests internes d’OpenAI montrent que GPT-5 « hallucine » dans environ une réponse sur dix lors de certaines tâches factuelles, lorsqu’il est connecté à Internet. Cependant, sans accès à la navigation web, GPT-5 est erroné dans près d’une réponse sur deux , ce qui devrait être inquiétant. Plus inquiétant encore, ces « hallucinations » peuvent également refléter des biais enfouis dans les ensembles de données. Par exemple, un master en droit pourrait « halluciner » des statistiques criminelles qui correspondent à des préjugés raciaux ou politiques simplement parce qu’il a appris à partir de données biaisées.
Il est à noter que les chatbots IA peuvent être et sont activement utilisés pour diffuser de la désinformation (voir ici et ici ). Selon une étude récente, les chatbots diffusent de fausses informations lorsqu’on les interroge sur des sujets d’actualité controversés dans 35 % des cas, soit près du double du taux de 18 % enregistré il y a un an ( ici ).
L’IA organise, ordonne, présente et censure l’information, influençant ainsi l’interprétation et le débat, tout en promouvant les points de vue dominants (moyens ou préférés) et en supprimant les alternatives, en supprimant discrètement les faits gênants ou en en inventant d’autres qui conviennent.
La question clé est : qui contrôle les algorithmes ? Qui fixe les règles pour les technophiles ? Il est évident qu’en facilitant la diffusion de fausses informations et de biais « d’apparence réaliste » et/ou en supprimant des preuves ou des argumentations essentielles, GenAI entraîne et entraînera des coûts et des risques sociétaux non négligeables, qui doivent être pris en compte lors de l’évaluation de ses impacts.
Construire des LLM de plus grande envergure ne mène nulle part
L’épisode ChatGPT-5 soulève de sérieux doutes et des questions existentielles quant à savoir si la stratégie fondamentale de l’industrie de l’IA générale, qui consiste à construire des modèles toujours plus volumineux sur des distributions de données toujours plus vastes, a déjà atteint son paroxysme.
Les critiques, dont le spécialiste des sciences cognitives Gary Marcus ( ici et ici ), soutiennent depuis longtemps que la simple mise à l’échelle des LLM ne mènera pas à l’IAG, et les regrettables échecs de GPT-5 confirment ces inquiétudes. Il est de plus en plus admis que les LLM ne reposent pas sur des modèles du monde réel robustes et fiables , mais plutôt sur une autocomplétion basée sur une recherche de motifs sophistiquée. C’est pourquoi, par exemple, ils ne sont toujours pas fiables aux échecs et continuent de commettre des erreurs ahurissantes avec une régularité surprenante.
Mon nouveau document de travail INET présente trois études de recherche révélatrices montrant que les nouveaux modèles GenAI, toujours plus volumineux, ne s’améliorent pas, mais se dégradent, et ne raisonnent pas, mais répètent des formules de raisonnement.
À titre d’exemple, un article récent de scientifiques du MIT et de Harvard montre que même entraînés sur l’ensemble de la physique, les modèles de niveau de confiance (LLM) ne parviennent même pas à découvrir les principes physiques généralisés et universels qui sous-tendent leurs données d’entraînement.
Plus précisément, Vafa et al. (2025) notent que les modèles de niveau de confiance qui suivent une approche « Kepler-esque » peuvent prédire avec succès la prochaine position orbitale d’une planète, mais ne parviennent pas à trouver l’explication sous-jacente de la loi de la gravité de Newton (voir ici ). Ils ont plutôt recours à des règles d’ajustement artificielles, qui leur permettent de prédire avec succès la prochaine position orbitale de la planète, mais ces modèles ne parviennent pas à trouver le vecteur de force au cœur de la théorie de Newton. L’article du MIT et de Harvard est expliqué dans cette vidéo . Les modèles de niveau de confiance ne peuvent pas déduire de lois physiques à partir de leurs données d’entraînement. Étonnamment, ils ne sont même pas capables d’identifier les informations pertinentes sur Internet. Au lieu de cela, ils les inventent.
Pire encore, les robots d’IA sont incités à deviner (et à donner une réponse incorrecte) plutôt qu’à admettre leur ignorance . Ce problème est reconnu par des chercheurs d’OpenAI dans un article récent . Deviner est récompensé, car, qui sait, on pourrait avoir raison. L’erreur est actuellement irréparable. Par conséquent, il serait peut-être plus prudent de parler d’« information artificielle » plutôt que d’« intelligence artificielle » lorsqu’on utilise l’acronyme IA. En résumé , c’est une très mauvaise nouvelle pour quiconque espère qu’une plus grande échelle – la création de LLM toujours plus importants – conduira à de meilleurs résultats (voir aussi Che 2025 ).
95 % des projets pilotes d’IA générative dans les entreprises échouent
Les entreprises s’étaient empressées d’annoncer des investissements dans l’IA ou de revendiquer des capacités d’IA pour leurs produits, espérant faire exploser le cours de leurs actions. Puis, on a appris que les outils d’IA ne remplissaient pas leur rôle et que les gens commençaient à s’en rendre compte (voir Ed Zitron ). Un rapport d’août 2025 intitulé « The GenAI Divide: State of AI in Business 2025 », publié par l’initiative NANDA du MIT , conclut que 95 % des projets pilotes d’IA générative en entreprise ne parviennent pas à générer de croissance du chiffre d’affaires. Comme le rapporte Fortune , « les outils génériques comme ChatGPT […] stagnent dans les entreprises, car ils n’apprennent pas et ne s’adaptent pas aux flux de travail ». Absolument.
En effet, les entreprises font marche arrière après avoir supprimé des centaines d’emplois et les avoir remplacés par l’IA. Par exemple, Klarna, l’entreprise suédoise « Achetez des burritos maintenant, payez plus tard », s’est vantée en mars 2024 que son assistant IA effectuait le travail de 700 employés (licenciés), pour les réembaucher (malheureusement, en tant que travailleurs indépendants) à l’été 2025 (voir ici ). Autre exemple : IBM, contraint de réembaucher du personnel après avoir licencié environ 8 000 personnes pour mettre en œuvre l’automatisation ( ici ). Des données récentes du Bureau du recensement des États-Unis, par taille d’entreprise, montrent que l’adoption de l’IA est en déclin parmi les entreprises de plus de 250 employés.
L’économiste du MIT Daren Acemoglu (2025) prédit un impact plutôt modeste de l’IA sur la productivité au cours des dix prochaines années et prévient que certaines applications de l’IA pourraient avoir une valeur sociale négative. « Nous aurons toujours des journalistes, des analystes financiers et des employés des RH », déclare Acemoglu . « Cela aura un impact sur de nombreux emplois de bureau liés à la synthèse de données, à la comparaison visuelle, à la reconnaissance de formes, etc. Et ceux-ci représentent environ 5 % de l’économie. »
De même, à partir de deux enquêtes à grande échelle sur l’adoption de l’IA (fin 2023 et 2024) portant sur 11 professions exposées (25 000 travailleurs sur 7 000 lieux de travail) au Danemark, Anders Humlum et Emilie Vestergaard (2025) démontrent, dans un récent document de travail du NBER , que les impacts économiques de l’adoption de l’IA de type Gen sont minimes : « Les chatbots IA n’ont eu aucun impact significatif sur les revenus ou les heures enregistrées dans aucune profession, les intervalles de confiance excluant les effets supérieurs à 1 %. Des gains de productivité modestes (gain de temps moyen de 3 %), combinés à une faible répercussion des salaires, contribuent à expliquer ces effets limités sur le marché du travail. » Ces résultats apportent une mise en perspective bien nécessaire de l’hyperbole selon laquelle l’IA de type Gen est en passe de s’imposer à tous nos emplois. La réalité est loin d’être aussi réaliste.
GenAI ne rendra même pas superflus les techniciens qui codent, contrairement aux prédictions des passionnés d’IA. Les chercheurs d’OpenAI ont constaté (début 2025) que les modèles d’IA avancés (dont GPT-4o et Claude 3.5 Sonnet d’Anthropic) ne font toujours pas le poids face aux codeurs humains. Les robots d’IA n’ont pas réussi à saisir l’ampleur des bugs ni à comprendre leur contexte, ce qui a conduit à des solutions incorrectes ou insuffisamment complètes.
Une autre étude récente de l’association à but non lucratif Model Evaluation and Threat Research (METR) révèle qu’en pratique, les programmeurs utilisant des outils d’IA début 2025 sont en réalité plus lents lorsqu’ils utilisent des outils d’assistance à l’IA, passant 19 % de temps de plus à utiliser GenAI qu’à coder seuls (voir ici ). Les programmeurs ont consacré leur temps à examiner les résultats de l’IA, à solliciter les systèmes d’IA et à corriger le code généré par l’IA.
L’économie américaine dans son ensemble est en pleine hallucination
Le lancement décevant de ChatGPT-5 soulève des doutes quant à la capacité d’OpenAI à concevoir et commercialiser des produits grand public pour lesquels les utilisateurs sont prêts à payer . Mais mon argument ne concerne pas uniquement OpenAI : l’industrie américaine de l’IA dans son ensemble s’est construite sur le principe que l’IA générale est imminente. Il suffit de disposer de suffisamment de ressources de calcul, c’est-à-dire de millions de GPU Nvidia pour l’IA, de centres de données et d’une électricité bon marché pour réaliser l’immense cartographie statistique nécessaire à la génération d’un semblant d’« intelligence ». Cela signifie que la « mise à l’échelle » (investir des milliards de dollars dans les puces et les centres de données) est la seule voie à suivre. Or, c’est précisément ce que les entreprises technologiques, les capital-risqueurs de la Silicon Valley et les financiers de Wall Street savent faire : mobiliser et dépenser des fonds, cette fois pour « mettre à l’échelle » l’IA générative et construire des centres de données pour répondre à la demande future attendue en matière d’IA.
Entre 2024 et 2025, les géants de la tech ont investi la somme colossale de 750 milliards de dollars dans les centres de données, et prévoient d’y consacrer 3 000 milliards de dollars entre 2026 et 2029 ( Thornhill 2025 ). Les « 7 magnifiques » (Alphabet, Apple, Amazon, Meta, Microsoft, Nvidia et Tesla) ont investi plus de 100 milliards de dollars dans les centres de données au deuxième trimestre 2025 ; la figure 1 présente les dépenses d’investissement de quatre de ces sept entreprises.
FIGURE 1
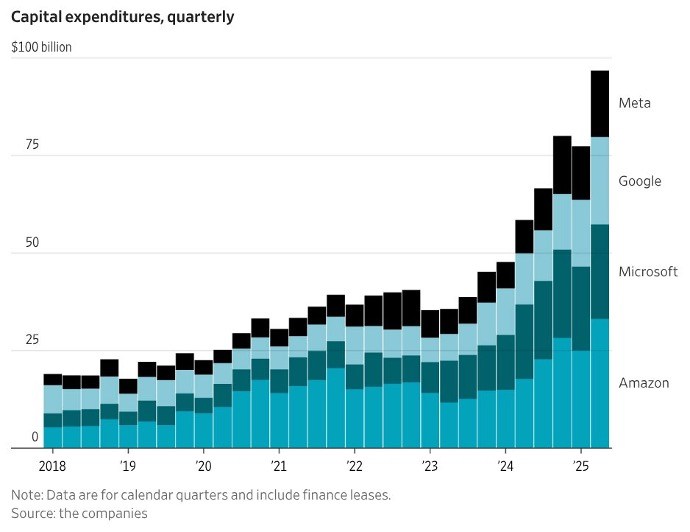
Christophe Mims (2025), https://x.com/mims/status/1951…
L’essor des investissements des entreprises dans les « équipements de traitement de l’information » est considérable. Selon Torsten Sløk, économiste en chef chez Apollo Global Management, la contribution des investissements dans les centres de données à la croissance (faible) du PIB réel américain a été équivalente à celle des dépenses de consommation au cours du premier semestre 2025 ( Figure 2 ). L’investisseur financier Paul Kedrosky constate que les dépenses d’investissement dans les centres de données d’IA (en 2025) ont dépassé le pic des dépenses en télécommunications atteint pendant la bulle Internet (de 1995 à 2000).
FIGURE 2
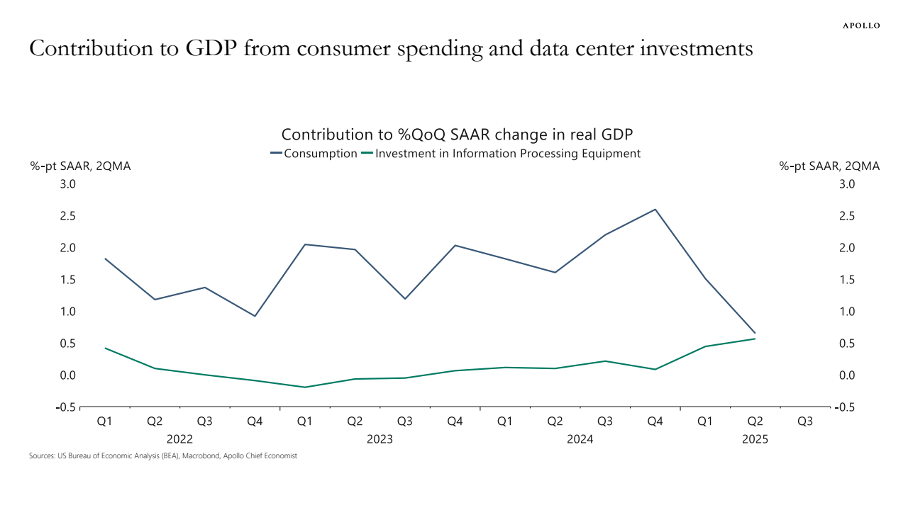
Source : Torsten Slok (2025). https://www.apolloacademy.com/…
Suite au battage médiatique et à l’exagération autour de l’IA, les actions technologiques ont explosé. L’indice S&P 500 a progressé d’environ 58 % en 2023-2024, principalement grâce à la croissance du cours des actions des Sept Merveilles. Le cours moyen pondéré de ces sept entreprises a augmenté de 156 % en 2023-2024, tandis que les 493 autres entreprises n’ont enregistré qu’une hausse moyenne de 25 %. Le marché boursier américain est largement porté par l’IA.
L’action Nvidia a grimpé de plus de 280 % au cours des deux dernières années, en raison de la forte demande de GPU de la part des entreprises d’IA. Nvidia, l’un des principaux bénéficiaires de cette demande insatiable pour la GenAI, affiche désormais une capitalisation boursière de plus de 4 000 milliards de dollars, soit la valorisation la plus élevée jamais enregistrée pour une société cotée en bourse. Cette valorisation est-elle pertinente ? Le ratio cours/bénéfice (PER) de Nvidia a culminé à 234 en juillet 2023 et a depuis baissé à 47,6 en septembre 2025 , un niveau historiquement très élevé (voir figure 3 ).
Nvidia vend ses GPU à des entreprises néocloud (telles que CoreWeave, Lambda et Nebius), financées par des prêts de Goldman Sachs, JPMorgan Chase, Blackstone et d’autres fonds d’investissement de Wall Street, garantis par les centres de données remplis de GPU. Dans des cas clés, comme l’explique Ed Zitron , Nvidia a proposé aux entreprises de néocloud, qui sont déficitaires, d’acheter des ressources informatiques cloud invendues d’une valeur de plusieurs milliards de dollars américains, soutenant ainsi efficacement ses clients – tout cela dans l’attente d’une révolution de l’IA qui n’a pas encore eu lieu.
De même, le cours de l’action Oracle Corp. (qui ne figure pas dans le « Magnificent 7 ») a augmenté de plus de 130 % entre mi-mai et début septembre 2025 suite à l’annonce de son accord de 300 milliards de dollars avec OpenAI pour une infrastructure de cloud computing. Le ratio cours-bénéfices d’Oracle a grimpé à près de 68 x, ce qui signifie que les investisseurs financiers sont prêts à payer près de 68 $ pour 1 $ des bénéfices futurs d’Oracle. Un problème évident avec cet accord est qu’OpenAI ne dispose pas de 300 milliards de dollars ; l’entreprise a enregistré une perte de 15 milliards de dollars entre 2023 et 2025 et devrait subir une perte cumulée supplémentaire de 28 milliards de dollars entre 2026 et 2028 (voir ci-dessous). La provenance des fonds pour OpenAI est incertaine. De manière inquiétante, Oracle doit construire l’infrastructure d’OpenAI avant de pouvoir percevoir des revenus. Si OpenAI ne peut pas payer l’énorme capacité de calcul qu’il a accepté d’acheter à Oracle, ce qui semble probable, Oracle se retrouvera avec une infrastructure d’IA coûteuse, pour laquelle il pourrait ne pas être en mesure de trouver d’autres clients, surtout une fois que la bulle de l’IA aura éclaté.
Les actions technologiques sont donc considérablement surévaluées. Torsten Sløk, économiste en chef chez Apollo Global Management, a averti (en juillet 2025) que les actions de l’IA étaient encore plus surévaluées que ne l’ étaient les actions des entreprises Internet en 1999. Dans un article de blog , il illustre comment les ratios cours-bénéfices de Nvidia, Microsoft et huit autres entreprises technologiques sont plus élevés qu’à l’époque de la bulle Internet (voir figure 3 ). Nous nous souvenons tous de la fin de la bulle Internet ; Sløk a donc raison de tirer la sonnette d’alarme face à l’engouement apparent du marché, alimenté par les « 7 Magnifiques », tous fortement investis dans le secteur de l’IA.
Les géants du numérique n’achètent pas ces centres de données et ne les exploitent pas eux-mêmes ; ils sont construits par des entreprises de construction, puis rachetés par des opérateurs qui les louent à OpenAI, Meta ou Amazon (voir ici ). Des fonds d’investissement de Wall Street comme Blackstone et KKR investissent des milliards de dollars pour racheter ces opérateurs, en utilisant des titres adossés à des créances hypothécaires commerciales comme source de financement . L’immobilier de centres de données est une nouvelle classe d’actifs en plein essor qui commence à dominer les portefeuilles financiers. Blackstone considère les centres de données comme l’un de ses « investissements les plus convaincants ». Wall Street apprécie les contrats de location de centres de données, qui offrent des revenus stables et prévisibles à long terme, versés par des clients notés AAA comme AWS, Microsoft et Google. Certains Cassandre mettent en garde contre une offre potentiellement excédentaire de centres de données, mais sachant que « l’avenir reposera sur GenAI », qu’est-ce qui pourrait mal tourner ?
Dans un rare moment de franchise, Sam Altman, PDG d’OpenAI, avait raison. « Sommes-nous dans une phase où les investisseurs sont globalement surexcités par l’IA ? » a-t-il déclaré lors d’un dîner-entretien avec des journalistes à San Francisco en août. « Je pense que oui. » Il a également comparé la frénésie actuelle des investissements dans l’IA à la bulle Internet de la fin des années 1990. « Je pense que quelqu’un va se faire avoir », a-t-il déclaré. « Quelqu’un va perdre une somme phénoménale – on ne sait pas qui… », mais (à en juger par les bulles précédentes) ce ne sera probablement pas Altman lui-même.
La question est donc : combien de temps les investisseurs continueront-ils à soutenir les valorisations exorbitantes des entreprises clés de la course GenAI ? Les bénéfices du secteur de l’IA restent faibles en comparaison des dizaines de milliards de dollars investis dans la croissance des centres de données. Selon une note de recherche optimiste de S&P Global publiée en juin, le marché GenAI devrait générer 85 milliards de dollars de revenus en 2029. Cependant, Alphabet, Google, Amazon et Meta dépenseront ensemble près de 400 milliards de dollars en dépenses d’investissement rien qu’en 2025. Dans le même temps, le chiffre d’affaires combiné du secteur de l’IA est à peine supérieur à celui du secteur des montres connectées ( Zitron 2025 ).
Et si GenAI n’était tout simplement pas rentable ?
Cette question est pertinente compte tenu de la baisse rapide des rendements des investissements colossaux consacrés à GenAI et aux centres de données, ainsi que de l’expérience utilisateur décevante de 95 % des entreprises ayant adopté l’IA.
Elliott , l’un des plus grands fonds spéculatifs au monde, basé en Floride , a déclaré à ses clients que l’IA était surfaite et que Nvidia était dans une bulle spéculative, ajoutant que de nombreux produits d’IA « ne seront jamais rentables, ne fonctionneront jamais correctement, consommeront trop d’énergie ou se révéleront peu fiables ». « Il y a peu d’utilisations réelles », a-t-il déclaré, hormis « la synthèse de notes de réunions, la génération de rapports et l’aide au codage informatique ». Il a ajouté qu’il était « sceptique » que les grandes entreprises technologiques continuent d’acheter des processeurs graphiques du fabricant de puces en si grand nombre.
Bloquer des milliards de dollars américains dans des centres de données axés sur l’IA, sans stratégie de sortie claire pour ces investissements en cas de fin de l’engouement pour l’IA, ne fait qu’accroître le risque systémique pour la finance et l’économie.
Alors que les investissements dans les centres de données stimulent la croissance économique américaine, celle-ci est devenue dépendante d’une poignée d’entreprises, qui n’ont pas encore réussi à générer un seul dollar de profit sur les capacités de calcul générées par ces investissements.
Les enjeux géopolitiques majeurs de l’Amérique tournent mal
Le boom de l’IA (bulle) s’est développé avec le soutien des deux principaux partis politiques aux États-Unis. La vision des entreprises américaines repoussant les frontières de l’IA et atteignant la GenAI en premier est largement partagée — en fait, il existe un consensus bipartisan sur l’importance pour les États-Unis de remporter la course mondiale de l’IA.
La capacité industrielle de l’Amérique dépend de manière critique d’un certain nombre d’États-nations adversaires potentiels, dont la Chine. Dans ce contexte, l’avance de l’Amérique dans la GenAI est considérée comme constituant un levier géopolitique potentiellement très puissant : si l’Amérique parvient à atteindre l’AGI en premier, selon l’analyse, elle peut se constituer un avantage écrasant à long terme, en particulier sur la Chine (voir Farrell ).
C’est pourquoi la Silicon Valley, Wall Street et l’administration Trump redoublent d’efforts pour mettre en œuvre la stratégie « AGI First ». Cependant, des observateurs avisés soulignent les coûts et les risques de cette stratégie. Eric Schmidt et Selina Xu s’inquiètent notamment, dans le New York Times du 19 août 2025, que « la Silicon Valley s’est tellement attachée à cet objectif [AGI] qu’elle s’aliène le grand public et, pire encore, passe à côté d’opportunités cruciales d’utiliser la technologie existante. En se focalisant uniquement sur cet objectif, notre pays risque de se laisser distancer par la Chine, bien moins soucieuse de créer une IA suffisamment puissante pour surpasser l’humain que d’exploiter la technologie actuelle. »
Schmidt et Xu sont légitimement inquiets. Sam Altman, d’OpenAI, illustre peut-être le mieux la situation critique de l’économie américaine, fantasmant sur l’implantation de ses centres de données dans l’espace : « On pourrait construire une grande sphère de Dyson autour du système solaire et se dire : « Tiens, ça n’a aucun sens de les installer sur Terre. » » Tant que ces « hallucinations » sur l’utilisation de satellites de collecte de l’énergie solaire pour capter (illimitément) l’énergie stellaire continueront de convaincre les investisseurs financiers crédules, le gouvernement et les utilisateurs de la « magie » de l’IA et de son industrie, l’économie américaine est condamnée.

Cette entrée a été publiée dans Statistiques douteuses , Fondamentaux économiques , Article invité , Perspectives d’investissement , Politique , Escroqueries ridiculement évidentes , Technologie et innovation surpar Yves Smith .
EN PRIME
S’abonner aux commentaires des articles38 commentaires
- IgnacioAltman d’OpenAI s’est vanté que l’AGI peut « découvrir de nouvelles sciences », car « je pense que nous avons déchiffré le raisonnement dans les modèles »,De toute évidence, Altman ignore tout de la science. J’ai par exemple effectué une recherche en IA sur un sujet dont j’étais expert il y a des années : le mouvement intercellulaire des virus chez les plantes. Avec Google AI, on obtient un récapitulatif d’idées plus ou moins connues. Surtout, il est sans réserve, sans esprit critique et sans aucune donnée expérimentale concrète déjà obtenue dans son contexte. La première chose qu’un chercheur doit faire est d’être très critique envers les données obtenues précédemment, en étant conscient que toutes ces données ont été obtenues dans des conditions expérimentales spécifiques qui aboutissent très souvent à des situations où le fonctionnement des choses est altéré ou contrôlé. En ce sens, de nombreux résultats de recherche sont des artefacts artificiels, souvent trompeurs et nécessitent davantage de vérifications et de contrôles. Je me souviens très bien d’un congrès (au Cap en 2001) sur les plasmodesmes, ces structures qui relient et communiquent entre les cellules végétales. Le mouvement intercellulaire des virus figurait parmi les principaux sujets abordés lors de cette petite réunion très spécialisée. Lors d’une session consacrée à ce sujet, un chercheur a exposé un vaste corpus de recherches mené par son laboratoire en utilisant une méthodologie de pointe. Ces recherches comprenaient des données déjà publiées (plusieurs articles) et, dans le même domaine, de nouvelles données à paraître prochainement, portant sur des conclusions importantes. Lors de la même session, un autre groupe de recherche, utilisant des méthodologies de pointe différentes, a obtenu des résultats suggérant des conclusions très différentes de celles du premier groupe. La discussion a été très intéressante et animée. Il était évident que l’un des chercheurs s’était plongé dans une accumulation d’artefacts expérimentaux. On peut parler de résultats hallucinatoires. Les humains peuvent donc parfois avoir des hallucinations, et c’est apparemment ce que les IA apprennent à faire : halluciner. Commencer une recherche par une simple reformulation d’idées, sans aucun esprit critique, me semble êtrange
